AI 與 EMS 派遣:當人工智慧進入生命之鏈的第一環

本文內容整理自 2026 年 6 月 22 日新光醫院急診科舉辦的全國 EMS/EM 救護討論會,由新光醫院急診科侯勝文醫師主講的〈AI 與 EMS 派遣:從哥本哈根到台北〉。
本文並不是單純討論「AI 能不能取代派遣員」,而是試著回答一個更務實的問題:
在一通可能關係到病人生死的 119 報案電話裡,AI 到底能幫上什麼忙?
近年生成式 AI、大型語言模型(Large Language Model, LLM)及 AI Agent 快速發展,使許多人第一次真正感受到人工智慧的實用性。不過,AI 在 EMS 的應用並不是從 ChatGPT 出現後才開始。
早在生成式 AI 普及以前,歐洲的 EMS 系統就已經利用機器學習與深度學習分析報案通話,希望從語音和文字內容中,更早辨識院外心跳停止(OHCA)。
從早期的通話辨識模型、語音轉文字,到現在的語音轉錄、品質管理、穿戴式裝置與多模態模型,AI 正逐漸進入緊急救護系統的不同環節。
但真正值得思考的,可能不是「AI 有多強」,而是:
- AI 的判斷能否轉化為實際行動?
- 派遣員是否願意相信警報?
- 系統能承受多少誤判與過度派遣?
- 國外訓練的模型,是否真的聽得懂臺灣的報案電話?
- 對臺灣而言,最值得優先導入的 AI 應用究竟是什麼?
生命之鏈:第一環沒有啟動,後面都不會發生
OHCA 的救治不是單一技術或單一醫療處置,而是一連串必須迅速銜接的行動。
「生存之鏈」包括:
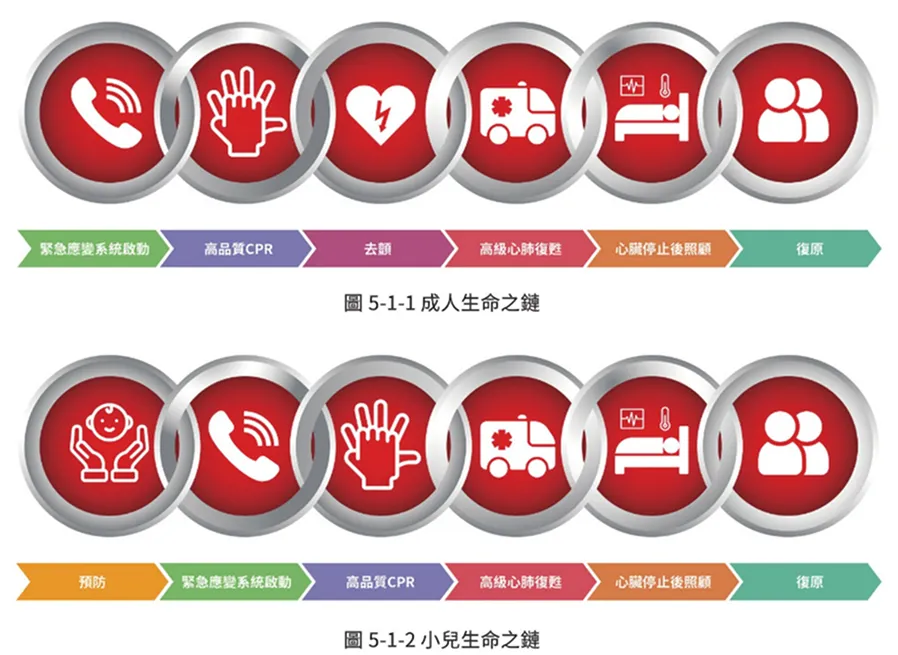
- 及早辨識心跳停止並啟動緊急應變系統
- 及早進行旁觀者 CPR
- 及早取得 AED 並完成去顫
- 提供高級心臟救命術
- 完成心跳恢復後的整合照護
- 復原
任何一環中斷,都會影響後續的存活機會。
根據簡報資料,美國每年發生超過 35 萬例 OHCA,整體平均存活率約為 8% 至 10%。即使面對相同疾病,不同 EMS 系統間的存活率仍可能存在 3 至 5 倍的差距。
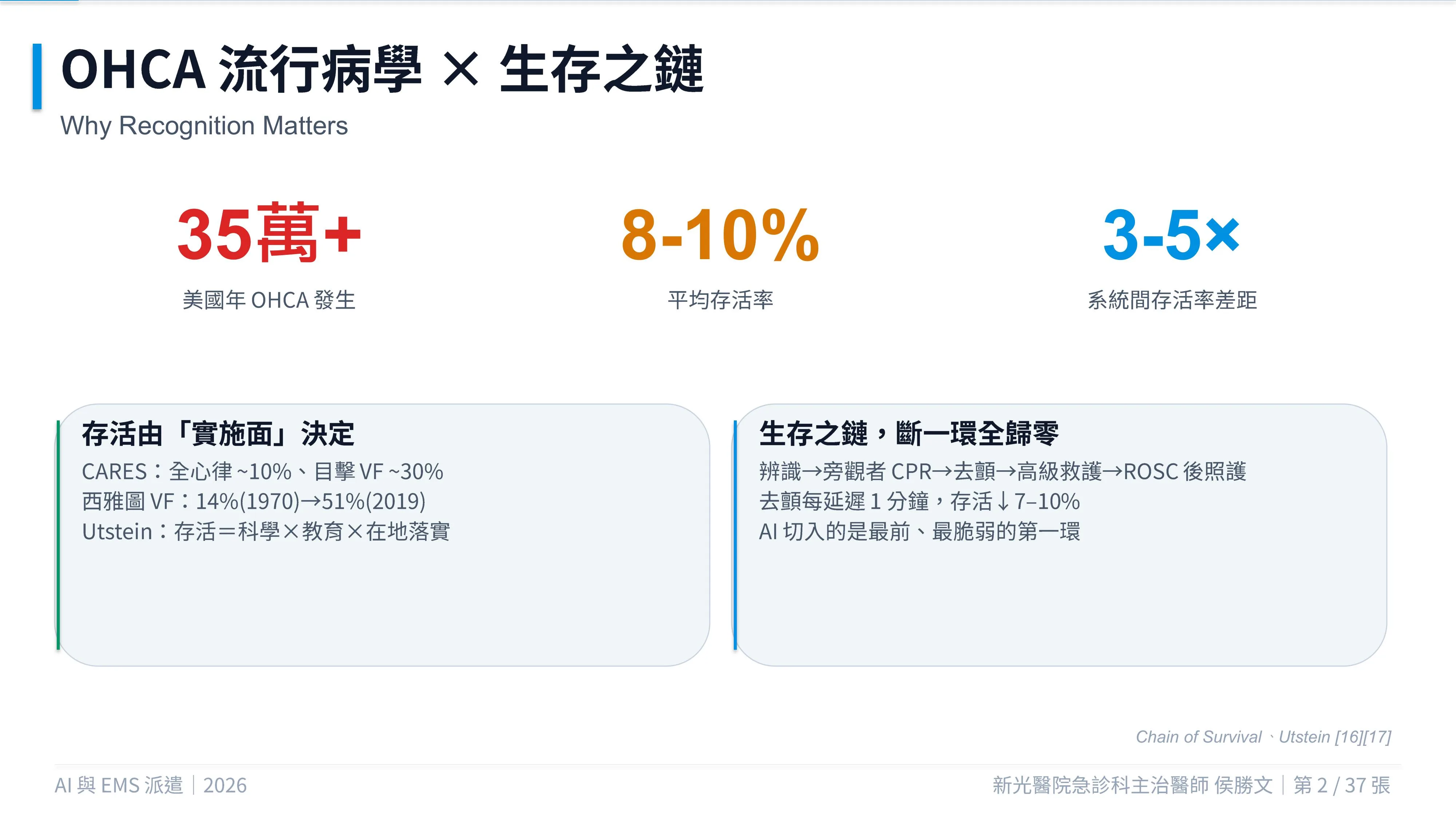
這代表影響病人結果的,不只是醫療科學本身,也包括教育訓練、派遣流程、民眾(旁觀者)反應、資源配置,以及各地是否真正將制度落實。
本次要討論的重點也是目前AI介入的部分,就是生存之鏈最前端的 「辨識」。
病人若沒有被辨識為 OHCA,派遣員便可能不會立即啟動派遣員指導 CPR,報案者不會開始壓胸,也可能不會有人去取得 AED。
救護車雖然已經出動,但最重要的幾分鐘可能已經流失。
這對於我目前在這個偏鄉跑救護的感受很深,出勤報疑似OHCA比到場發現OHCA的比例中,反而疑似OHCA到場為OHCA的比例來的更少。
去顫每延遲一分鐘,病人的存活機會可能下降約 7% 至 10%。因此,對 OHCA 而言,勤指並不只是「接電話與派車」的行政中心,而是病人救治真正開始的地方。
以我自己在跑救護的案例當中,尤其又身處平均年齡較高與外移與外籍工作人口較多的鄉鎮,無論病人年紀與否,到場有bystander CPR 真的是少之又少,再加上長照資源介入程度的差異,導致患者於家中被發現為第一時間的OHCA比率來的非常非常低。
往往都是發現患者怪怪的,先打給老闆(居服員、雇主),然候再透過跨區的轉報(因為雇主或是家屬大多都在外地工作),代為報案
一層一層資訊的傳遞,時間的流失,都造成不可逆的結果。
OHCA 的電話辨識,比想像中困難
OHCA 派遣辨識的核心原則,「No-No-GO」:
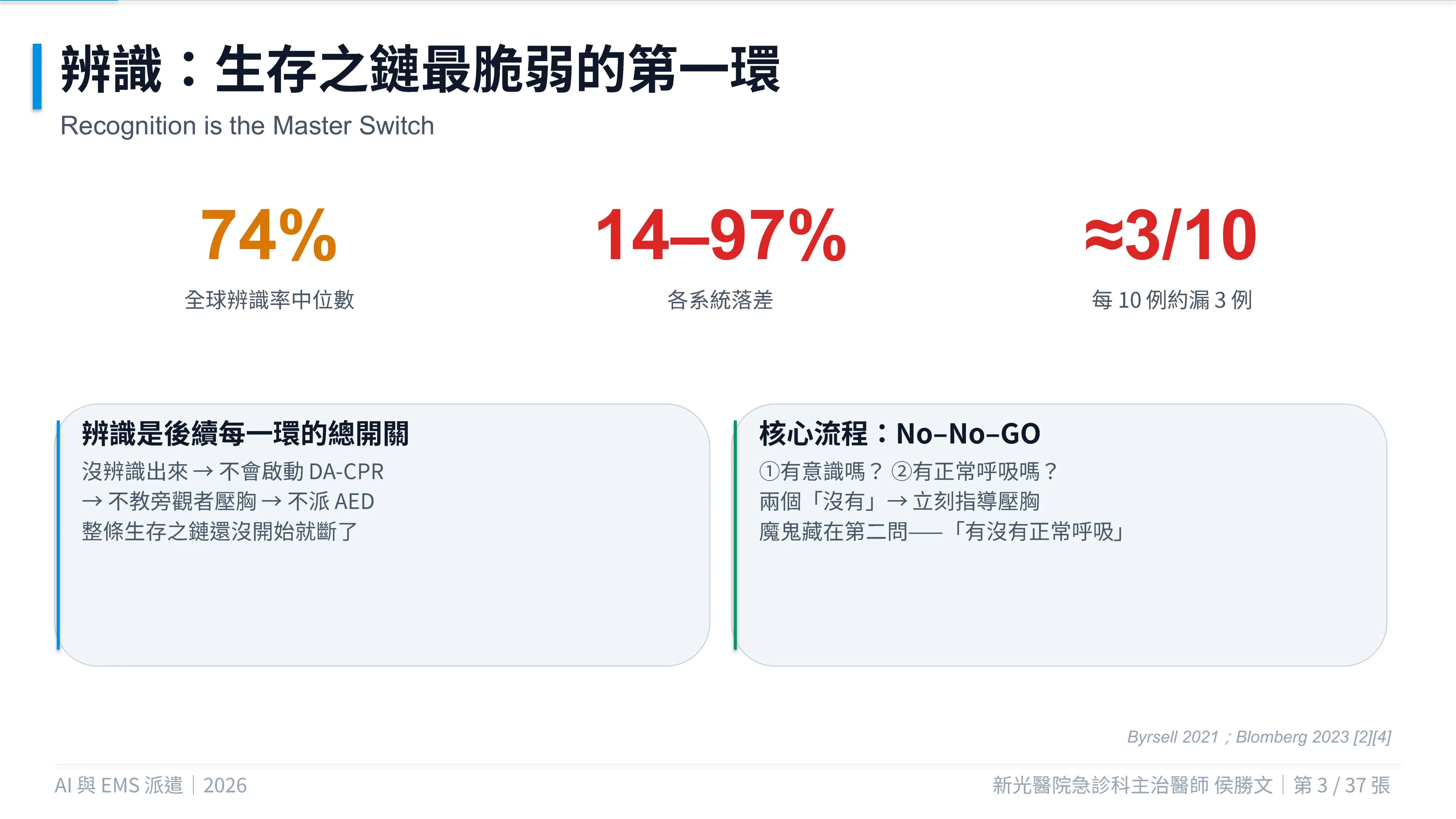
- 病人有意識嗎?沒有。
- 病人有正常呼吸嗎?沒有。
- 兩個答案都是「沒有」,立即開始指導壓胸。
流程看起來非常簡單,但真正困難的地方在於,派遣員並不在病人旁邊。
派遣員必須透過電話,引導一名可能極度緊張、哭泣、語意混亂,甚至根本不在病人身旁的報案者,完成意識與呼吸評估。
OHCA 病人通常也無法自行報案,因此派遣員接收到的資訊,必然經過第三人的觀察與描述。只要報案者提供了錯誤或不完整的資訊,無論是人類或 AI,都很難作出正確判斷。
目前全球 OHCA 電話辨識率的中位數約為 74%,各 EMS 系統間則可能從 14% 到 97% 不等。
換句話說,即使在現代 EMS 系統中,每 10 名 OHCA 病人,仍可能有接近 3 名沒有在報案階段被辨識出來。
人類與 AI 共同的盲點:瀕死式呼吸
OHCA 辨識最常見的陷阱之一,是瀕死喘息(agonal breathing)。

心跳停止後,病人的腦幹可能仍有短暫殘餘活動,產生不規則、緩慢、喘息或類似打鼾的呼吸動作。
對一般民眾而言,看到胸口仍有動作或聽到喘息聲,最直覺的回答通常是:
「他還有呼吸。」
但這並不代表病人具有正常且有效的呼吸。
瀕死喘息甚至會形成一個反直覺的現象:有人親眼目擊病人倒下,OHCA 反而可能更難被辨識。
因為目擊者看見病人在倒下後仍有喘息或抽動,便認為病人尚未心跳停止,進而延遲 CPR。
研究顯示,漏掉 OHCA 的通話中,派遣員主動詢問呼吸狀態的比例約為 65%;成功辨識 OHCA 的通話中,詢問比例則可達 84%。
這也說明,比起單純等待報案者描述,派遣員是否主動、明確而具體地追問「正常呼吸」,可能才是辨識成功的關鍵。
更值得注意的是,瀕死喘息不只是人類的盲點。
AI 同樣是根據報案者的語句及通話資訊判斷。當報案者明確表示「病人有呼吸」,模型也可能被帶往錯誤方向。
因此,AI 並不是一個能看穿所有問題的神奇工具。當輸入資訊本身錯誤時,模型通常也只能在錯誤資訊上作出推論。
AI 在 EMS 派遣中的三種應用層次
侯醫師將目前 AI 在 EMS 派遣中的應用,大致分成三個層次。

一、即時辨識
即時辨識是目前研究最多,也是最容易被理解的應用。
系統在報案電話進行的同時,完成語音轉文字,並分析通話中是否出現 OHCA 的關鍵特徵。
例如:
- 病人沒有反應
- 病人沒有正常呼吸
- 突然倒下
- 呼吸聲異常
- 報案者描述病人正在喘息、抽動或打鼾
- 派遣員尚未完成 No-No-GO 的關鍵問句
當模型判斷案件可能是 OHCA 時,便在派遣畫面上顯示警示,提醒派遣員再次確認。
這類系統的重點不是自動取代派遣員,而是像坐在旁邊的第二名觀察者,在高壓且資訊量龐大的通話中,協助避免遺漏。
其實我覺得不應該只有OHCA被導入,應該連無線電的回報都應該有逐字輸出的功能,畢竟聽打有時候就是會遺漏。
二、品質回饋迴圈
第二種應用是事後品質管理。
目前各縣市勤指已累積大量錄音、救護紀錄與案件資料,但依賴人工逐案聽取與審查,通常需要投入大量時間及人力。
AI 可以先協助:
- 將通話錄音轉成逐字稿
- 判斷是否完成意識與呼吸評估
- 計算從接聽到 OHCA 辨識的時間
- 計算從接聽到開始 DA-CPR 的時間
- 標記未詢問正常呼吸的案件
- 找出中斷、延遲或未完成 CPR 指導的原因
- 比較不同派遣員、分隊或縣市的常見缺失
更重要的是,AI 不只能逐案打分數。
當系統分析數百、數千甚至數萬件案件後,可能發現某個單位共同存在的系統性問題,例如:
- 對瀕死喘息的追問不足
- 遇到高齡報案者時較容易中斷指導
- 國語與臺語混用時辨識率下降
- 某類話術容易讓報案者拒絕壓胸
- 特定時段的辨識速度較慢
- 某些分隊在 CPR 品質上有一致性缺失
對臺灣而言,品質回饋可能比直接導入即時 OHCA 警報更有價值。
因為它的風險較低,不會直接影響當下派遣決策,卻可以減少品管人員負擔、統一審查標準,並逐步建立臺灣自己的 EMS 語料庫。
三、穿戴式裝置偵測
第三種應用,是透過智慧手錶或其他穿戴式裝置直接偵測異常。
OHCA 派遣最大的限制,是病人通常無法自行報案。如果病人獨自在家,周圍沒有人看見,即使派遣系統再準,也不會報案進入 119。
若穿戴式裝置能偵測脈搏消失、異常活動或失去反應,便可能自動啟動緊急通報。
這相當於把 OHCA 偵測的起點,從「有人發現並打電話」,往前移到病人的手腕。
不過,穿戴式裝置也會面臨誤報、位置資訊、個人隱私、裝置普及率及 EMS 系統介接等問題。
因此,短期內它比較可能扮演新的資料來源,而不是完全取代傳統報案流程。
加上現在vibe codeing 的盛行與低門檻,現行各分隊都有一些 OHCA品管工具,或是現場的給藥紀錄等,可以做一個系統性的統整,令資料分析可以更全面,比較容易找出到底系統上哪裡有問題,哪裡需要改善的落實6環的每一環。
AI 真的比派遣員更會辨識 OHCA 嗎?
Blomberg 2019:模型比人更敏感,也能更快辨識
2019 年發表於《Resuscitation》的研究,是早期 AI 分析真實 EMS 通話的重要驗證。

研究中的機器學習模型:
- 敏感度為 84.1%
- 特異度為 97.3%
- 派遣員敏感度為 72.5%
- AI 辨識時間約為 44 秒
- 派遣員辨識時間約為 54 秒
表面上看來,AI 不只辨識得更多,也辨識得更快。
不過,這是一項回顧性研究。
研究可以證明模型在既有資料中的表現,卻無法回答一個更重要的問題:
當 AI 警報真的出現在派遣員面前時,派遣員會採取不同的行動嗎?
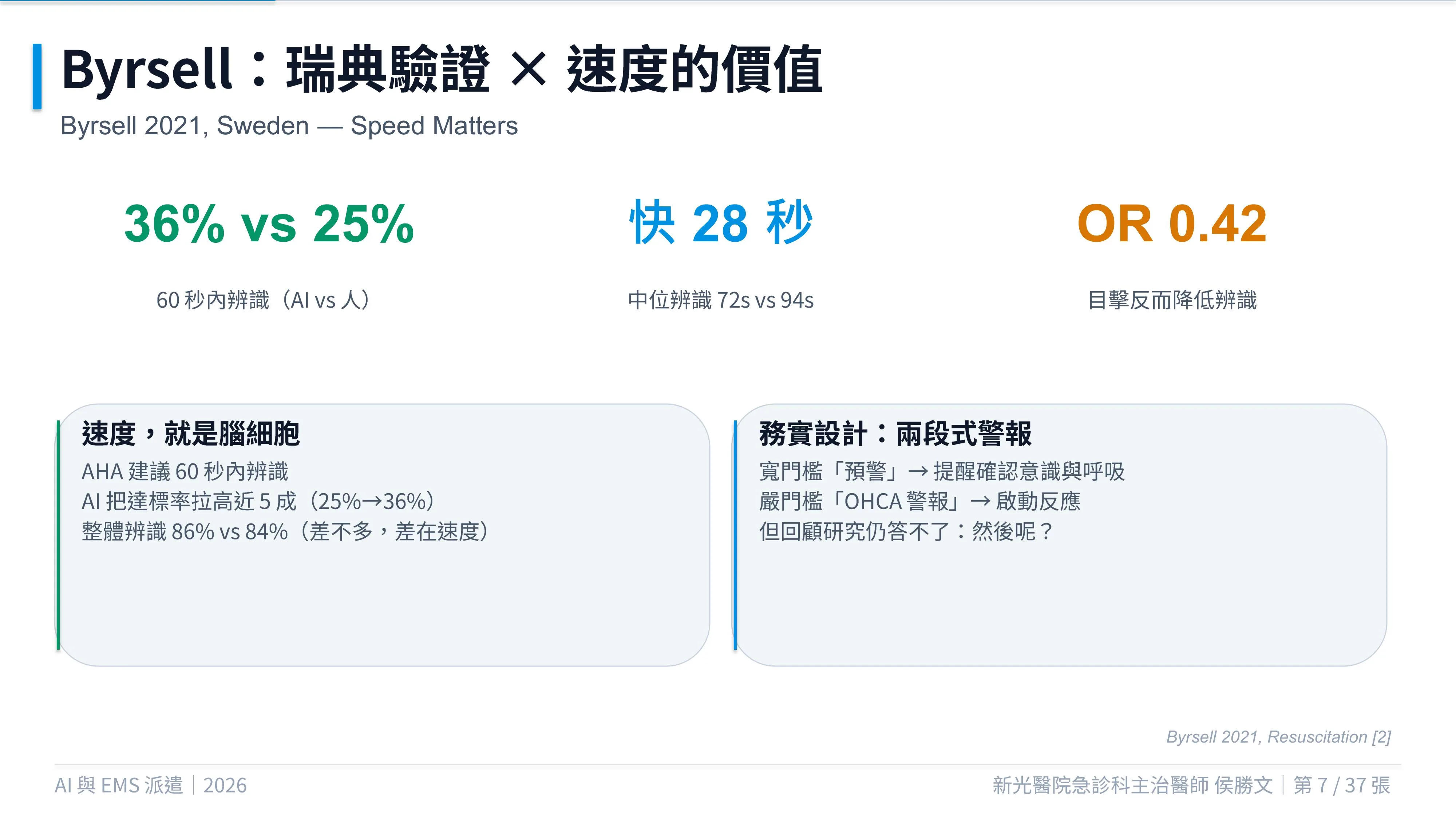
Byrsell 2021:真正的差異可能在速度
瑞典的研究顯示,AI 與派遣員的整體 OHCA 辨識率差異不大,分別約為 86% 與 84%。
但在 60 秒內完成辨識的比例:
- AI 為 36%
- 派遣員為 25%
辨識時間中位數則約相差 28 秒:
- AI 約 72 秒
- 派遣員約 94 秒
這表示 AI 的價值不一定是「找到更多 OHCA」,也可能是「更早提醒」。
在 OHCA 救治中,20 秒或 30 秒看起來很短,但若能更早開始壓胸、更早派遣 AED,累積起來便可能影響病人結果。
全球第一個 AI 派遣隨機對照試驗,結果卻是陰性
2021 年,哥本哈根進行了全球第一個 AI 輔助 EMS 派遣隨機對照試驗。
研究共納入:
- 169,049 通緊急電話
- AI 標記 5,242 通疑似 OHCA
- 最後確認 654 例 OHCA
系統會持續分析所有通話。當 AI 判斷案件疑似 OHCA 時,研究再隨機決定是否將警報顯示給派遣員。
也就是說,兩組都有相同的 AI 模型,差異只在於派遣員能不能看見警報。
結果顯示,模型本身確實比派遣員更敏感:
- AI 敏感度為 85%
- 派遣員敏感度為 77.5%
但是,派遣員實際辨識 OHCA 的比例並沒有顯著改善:
- 看得到 AI 警報的介入組:93.1%
- 看不到 AI 警報的對照組:90.5%
DA-CPR 的啟動率與啟動時間,同樣沒有明顯差異。
因此,這項研究的主要結果是陰性。
但把它解讀成「AI 沒有用」,可能過於簡化。
真正的瓶頸不是模型,而是人機互動
研究中的 AI 雖然敏感,但陽性預測值(Positive Predictive Value, PPV)只有 17.8%。
換句話說,AI 每發出 5 至 6 次 OHCA 警報,只有大約 1 次是真的。
相較之下,派遣員判斷 OHCA 的 PPV 約為 55.8%。
如果派遣員完全依照 AI 警報行動,雖然可能多辨識一些 OHCA,卻也會增加約 1,519 次高優先派遣,使總出車量增加約 2.7%。
對車輛與人力充足的都會區而言,增加 2.7% 的出車量可能仍可承受;但在偏鄉或救護資源有限的地區,一次錯誤的高優先派遣,可能造成救護責任區長時間沒有可用車輛。
派遣員在長期使用後,也會逐漸發現警報經常出錯。
當警報多數是假的,派遣員便會開始忽略提示,形成所謂的警報疲勞(alarm fatigue)。
因此,AI 系統成敗的關鍵不只在於敏感度、特異度或模型大小,還包括:
- 警報如何呈現
- 什麼時候出現
- 是否提供判斷理由
- 派遣員是否理解模型限制
- 錯誤警報會增加多少工作負荷
- 系統如何建立使用者的信任
- 派遣員是否能回饋模型判斷
一個模型即使在研究報告中的數字很好看,若使用者不相信、無法理解,或警報無法轉化成下一步行動,它在真實系統中的效益仍可能接近零。
身處偏鄉非常有感
-
-
人力難題
以我現在所在的縣市而言,分隊與分隊的距離當然無法跟六都相提並論,平日熱門時段都有可能會發生大亂鬥1的情況,更不用說當量能吃緊時這個系統能不能負擔的起這樣的工作負荷
-
辨識不等於行動
AI 可以提醒派遣員「這可能是 OHCA」,但完成辨識之後,仍需要說服報案者開始 CPR。
現場報案者可能因為害怕、情緒崩潰、年齡、語言、宗教、環境限制或擔心傷害病人,而拒絕或無法完成壓胸。
因此,真正完整的流程應該是:
- AI 或派遣員辨識疑似 OHCA
- 派遣員確認意識及正常呼吸
- 派遣員明確告知需要立即 CPR
- 說服報案者將病人移到適當位置
- 指導正確壓胸
- 持續維持報案者的配合
- 引導取得 AED
- 與到場救護人員完成交接
AI 即使提升第一步的辨識率,也不代表後續每一步都會自動改善。
這也是為什麼 EMS 的 AI 不能只用模型準確率評估。
真正需要衡量的指標,還應包含:
- OHCA 辨識時間
- DA-CPR 啟動率
- 開始第一次壓胸的時間
- 報案者拒絕率
- AED 取得與使用率
- 不必要高優先派遣的增加量
- 派遣員對警報的採納率
- 派遣員工作負荷及警報疲勞
- 病人存活與神經學預後
臺灣已逐漸接近辨識率的天花板
根據簡報引用的消防署資料,臺灣全國 OHCA 派遣辨識率,在 2021 年約為 66.55%。
當時 19 個統計縣市中,只有 5 個達到 AHA 建議的 75% 辨識率。
簡報引用的 2026 年 5 月消防署內部統計則顯示:
- 全國辨識率提升至約 81.2%
- 19 個縣市中已有 17 個達到 75%
五年間提升接近 15 個百分點,是非常明顯的進步。
但這個成果也帶來另一個問題:當既有派遣系統已經表現良好,單純加入即時 AI 辨識,能改善的空間可能越來越有限。
這就是所謂的天花板效應。
如果系統原本只能辨識六成 OHCA,AI 或許有機會帶來明顯改善;但當辨識率已超過八成,剩下的案件通常是最困難、資訊最不足的案例。
例如:
- 報案者不在病人身旁
- 報案者提供錯誤資訊
- 病人被誤認為酒醉或睡著
- 報案者表示仍有呼吸
- 語言無法溝通
- 外籍看護無法描述狀況
- 背景環境過度吵雜
- 通話中斷
這些問題未必能靠更大的模型直接解決。
臺灣的特殊問題:AI 聽得懂誰的語言?
國外 OHCA 辨識模型多在北歐或韓語環境中開發,沒有使用臺灣 119 報案語料訓練。
然而,臺灣的緊急報案可能同時包含:
- 國語
- 臺語
- 客語
- 原住民族語
- 國語與臺語混用
- 外籍移工或外籍看護使用的華語
- 英語、越南語、印尼語等其他語言
同一句「沒有正常呼吸」,在不同地區、語言及生活習慣中,可能有完全不同的說法。
例如臺語中的「伊攏無咧喘」、「叫袂醒」、「人硬去矣」,未必能被只用標準華語訓練的模型正確理解。
Blomberg 2023 的分析指出,約 22.7% 的 AI 偽陰性案件涉及語言障礙。
這表示語言不只是語音辨識技術問題,也是一個公平性問題。
若模型只對標準國語表現良好,它可能恰好在高齡者、偏鄉居民、原住民族、外籍移工或其他最需要系統協助的族群中失效。
因此,臺灣若要導入 AI 派遣,不應直接購買國外模型後期待它自然適應。
更合理的作法,是使用臺灣各地實際報案資料建立本土語料庫,並依不同地區的語言分布訓練及驗證。
北部都會區的模型,不一定能直接套用到客語使用較多的桃竹苗,或臺語使用比例較高的中南部地區。
我的觀察/想法:
可補充你所在縣市常見的報案語言,以及第一線是否經常遇到外籍看護、長者或方言溝通問題。也可以討論視訊 119 是否能提供比單純語音更多的現場資訊。
對臺灣而言,品質管理可能比即時警報更值得先做
依照簡報提出的優先順序,臺灣可以採取三階段路徑。
第一優先:AI 輔助品質回饋
先將 AI 用於事後錄音分析與品質管理。
優點包括:
- 不會直接干預即時派遣決策
- 醫療與勤務風險較低
- 能減輕人工聽取錄音的負擔
- 能統一不同審查者的評分標準
- 能快速找出系統性問題
- 能建立本土語料庫
- 能作為後續模型訓練資料
這可能是目前投報率最高,也最容易開始的做法。
第二優先:本土化即時辨識
在累積足夠本土語料後,再建立即時 OHCA 辨識模型。
建議先以影子模式(shadow mode)運行:
- AI 持續判斷案件
- 先不將結果顯示給派遣員
- 事後比較 AI 與派遣員結果
- 分析偽陽性與偽陰性
- 驗證不同語言、地區與時段的表現
確認模型安全性及可接受的誤判成本後,再逐步開放輔助警報。
警報也不一定只能分成「OHCA」與「非 OHCA」,可以採兩階段設計:
- 寬門檻預警:提醒派遣員確認意識與正常呼吸
- 嚴格 OHCA 警報:建議立即啟動 DA-CPR 流程
這樣可以降低模型直接下診斷所帶來的風險。
第三優先:穿戴式裝置與多模態資訊
未來 EMS 系統還需要準備接收:
- 智慧手錶自動警報
- 手機位置及活動資訊
- 視訊報案
- 現場影像
- AED 資訊
- 公共場所監視器或感測器
- 社區志願應變者位置
目前 EMS 派遣 AI 的最大限制,經常不是演算法不夠強,而是輸入資訊太少。
當派遣員只有一通音質不穩定的電話,所有判斷都受限於報案者的描述。
若未來能加入視訊、穿戴裝置或其他感測資訊,人類與 AI 都可能得到更完整的判斷依據。
AI 導入 EMS 前,不能忽略的倫理與治理問題
AI 進入 EMS 後,會接觸大量高度敏感的資料,包括:
- 報案者姓名與電話
- 病人健康狀況
- 地址與即時位置
- 通話錄音
- 現場影像
- 救護紀錄
- 病人後續醫療結果
因此,導入 AI 不只是購買軟體或訓練模型,也涉及完整的資料治理。
需要事先釐清:
- 誰可以存取錄音及逐字稿?
- 資料保存多久?
- 是否能用於模型訓練?
- 是否需要去識別化?
- 模型與資料是否放在境外伺服器?
- AI 判斷錯誤時由誰負責?
- 派遣員能否推翻 AI 建議?
- 是否完整保留模型警報及人工決策紀錄?
- 如何監測模型對不同語言及族群的偏差?
- 模型更新後是否需要重新驗證?
2026 年一項包含 18 個國家、27 位 EMS 專家、經過 3 輪調查的德菲研究顯示,專家對 AI 在通訊、臨床、教育、管理及營運上的應用大致能形成共識。
但在 15 項倫理議題中,只有 8 項達成共識。
爭議集中在病人自主、知情同意、資料隱私及偏見偵測。
這反映一個現實:技術的發展速度,往往快過制度與標準建立的速度。
第一線人員很可能在沒有完整 SOP、法律解釋或責任分工之前,就已經被要求開始使用 AI。
AI 不會取代派遣員,但會重新定義派遣員的工作
現階段 AI 最適合的角色,仍是協作工具。
它可以:
- 持續聆聽所有通話
- 提醒可能遺漏的關鍵問題
- 找出疑似 OHCA
- 自動整理通話內容
- 協助事後品管
- 分析大量案件中的共同缺失
- 提供教育訓練素材
- 減少重複且耗時的行政工作
但它仍無法完全取代人類在以下方面的能力:
- 理解複雜情境
- 安撫報案者
- 說服民眾進行 CPR
- 在資訊不足時承擔決策
- 權衡區域救護資源
- 面對例外與倫理衝突
- 對決策結果負責
未來的派遣員可能不再只是按照固定流程詢問,而需要具備監督 AI、判讀模型限制與處理例外的能力。
換句話說,派遣員會逐漸成為 AI 系統的守門員。
真正重要的能力,也許不是會不會寫程式,而是能不能問出正確的問題:
- 這個模型是用什麼資料訓練的?
- 它在哪些族群中容易失效?
- 偽陽性與偽陰性的代價分別是什麼?
- 它改善的是模型指標,還是病人結果?
- 這項功能真的減少工作,還是製造更多警報?
- 當 AI 與我的判斷不同時,應該如何處理?
- 系統是否留下足夠紀錄,讓錯誤能被檢討?
我的想法:AI 最有價值的地方,可能不是代替人做決定
以下段落建議改成自己的觀點。
我認為,AI 對 EMS 最大的價值,不一定是直接告訴派遣員「這是不是 OHCA」,而是讓原本難以被看見的系統問題變得可量化。
過去的品質管理,往往只能抽查少量案件。即使發現問題,也很難確定這是單一個案,還是整個系統反覆發生的缺失。
AI 若能分析大量通話,便可能協助我們回答:
- 我們最常在哪一個問題上延遲?
- 哪一類報案者最容易無法完成 CPR?
- 哪一種話術最有效?
- 哪些案件經常被誤判?
- 哪些差異來自個人,哪些差異來自制度?
- 教育訓練完成後,實際表現是否改善?
這些問題未必像「AI 自動辨識 OHCA」那麼吸引目光,卻可能更直接地改善整體 EMS 品質。
請補入自己的實務觀點:
我在第一線觀察到的問題是________。
我認為目前最浪費人力的流程是________。
如果能用 AI 協助,我最希望先改善________。
但我最擔心的風險是________。
我認為無論 AI 發展到什麼程度,最後仍必須由人負責的工作是________。
結語
從哥本哈根的機器學習模型,到臺灣正在發展的 AI 品管與派遣應用,可以看見人工智慧確實有能力協助 EMS。
但研究也清楚提醒我們:
模型比人準,不代表系統一定會變好;辨識出 OHCA,也不代表報案者就會開始 CPR。
真正影響結果的,是演算法、派遣流程、教育訓練、人機互動、資源配置與在地語言能否形成完整的系統。
AI 不應被視為萬能解答,也不應因為一次陰性研究就被完全否定。
更合理的態度,是先確認我們想解決什麼問題,再選擇適當的工具。
對臺灣而言,或許最務實的起點不是追求一套看起來最先進的即時警報系統,而是先利用 AI 做好品質回饋、建立本土語料、理解各縣市真正的弱點。
當資料、制度與使用者信任逐漸成熟後,再將 AI 放進即時派遣流程。
最後決定病人是否能得到幫助的,仍然不是模型跑出了多少分數,而是警報出現之後,有沒有人作出正確的行動。
資料來源與延伸閱讀
本文主要依據:
- 侯勝文醫師,〈AI 與 EMS 派遣:從哥本哈根到台北〉,2026 年新光醫院急診科全國 EMS/EM 救護討論會。
- Blomberg 等人,2019 年發表於《Resuscitation》的 EMS 通話機器學習回顧研究。
- Byrsell 等人,2021 年發表於《Resuscitation》的瑞典 OHCA 辨識研究。
- Blomberg 等人,2021 年發表於《JAMA Network Open》的 AI 輔助 EMS 派遣隨機對照試驗。
- Blomberg 等人,2023 年對 OHCA 偽陰性及辨識障礙的分析。
- 內政部消防署,2021 年全國 DA-CPR 品質管理統計。
- 內政部消防署,2026 年 5 月內部統計資料。
- AlShammari 等人,2026 年 EMS 人工智慧應用國際德菲共識研究。
發布前建議補上各篇論文的 DOI 或正式連結,並明確註記 2026 年數據為演講簡報引用的內部統計。